配置日志解析规则
日志易内置了常用的日志解析规则,能够识别、解析常见的日志格式。对于日志易预置规则不支持的日志格式,用户可以在产品页面的“设置”标签下的“日志格式”标签里配置日志格式解析规则,抽取自定义字段。
一些重要概念
event(事件): 一条日志称为一个事件
timestamp(时间戳): 这里的timestamp指日志本身的时间戳而不是进入系统的时间戳
field(字段): 即通过日志易系统抽取出来的字段,由字母数字下划线组成,例如apache中clientip字段
appname:appname用来标识一个日志格式,由字母数字下划线组成,在上传日志的时候需要指定对应的appname
logtype:logtype可以认为是给您的日志格式起的一个别名,同样也由字母数字下划线组成(不能设置为security, appname, hostname, timestamp, tag, raw_message, index)您在左侧字段栏和搜索栏中可以通过logtype.field来引用
日志的解析
日志解析的主要作用是抽取您认为重要的字段,这就需要您熟悉解析规则的配置。例如这样一条日志:
192.168.1.103 - - [01/Aug/2014:12:07:39 +0800] "GET / HTTP/1.1\" 200 3228 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET CLR 1.1.4322; .NET4.0C)"
要抽取出如下字段:
1 "ua" : "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET CLR 1.1.4322; .NET4.0C)"
1.1 "os" : "Windows XP"
1.2 "os_v" : "Windows XP"
1.3 "browser" : "IE"
1.4 "browser_v" : "IE 8.0"
1.5 "device" : "Other"
2 "clientip" : "192.168.1.103"
3 "status" : 200
4 "resp_len" : 3228
5 "method" : "GET"
6 "version": "1.1"
需要您在数据接入系统前即配置好解析规则,方便您后续根据日志字段来做相关的处理。 下面介绍一下如何配置您的解析规则。
进入“设置”-“字段提取”,可以看到当前的所有字段提取规则列表,自定义规则可以进行编辑、删除等操作。
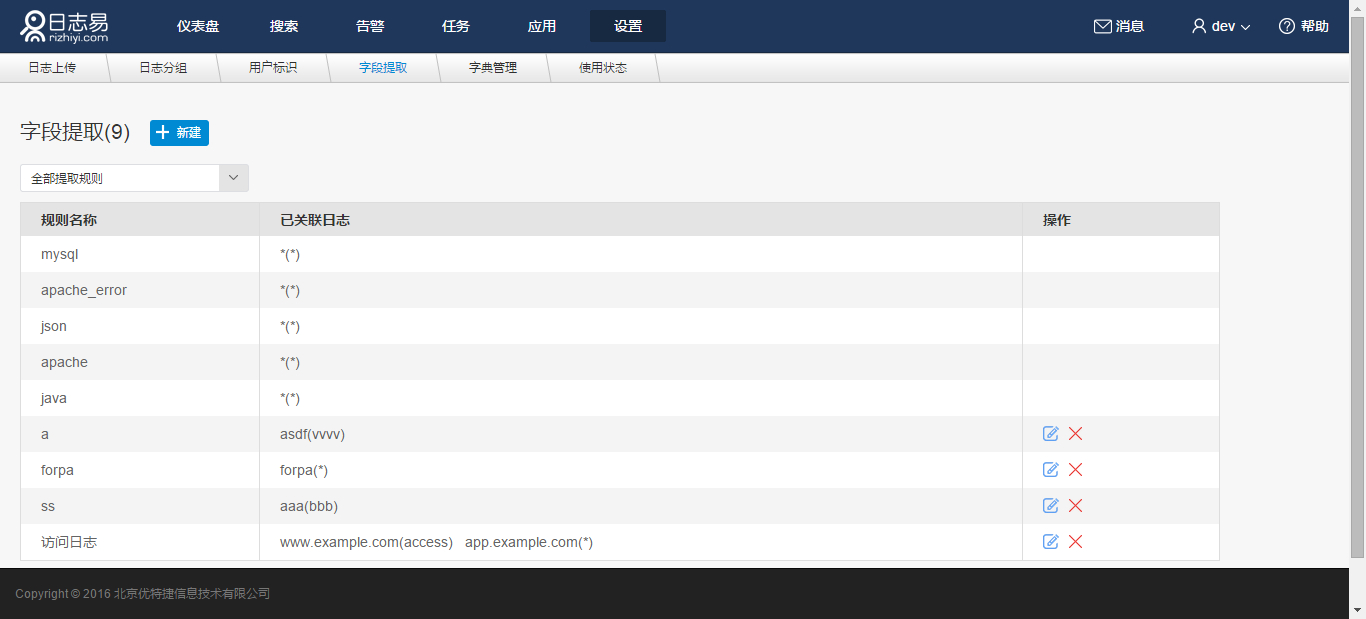
新建规则流程
点击“新建”,默认“不使用已有规则”,点击“下一步”
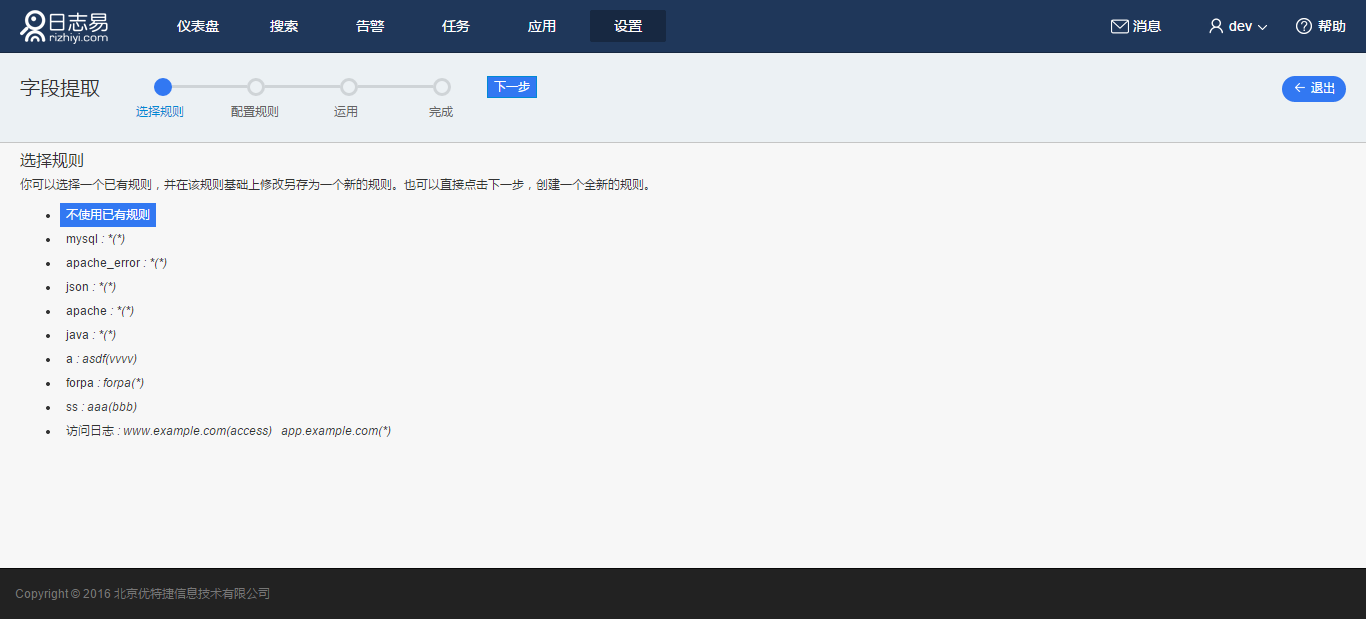
进入空白“配置规则”页,页面最下方为已入库的日志列表,您可以按需选择过滤时间段,输入搜索字符串进行过滤。在搜索结果中,点击某条日志“选为日志样例”,该行日志显示在页面上端的“日志样例”文本框;
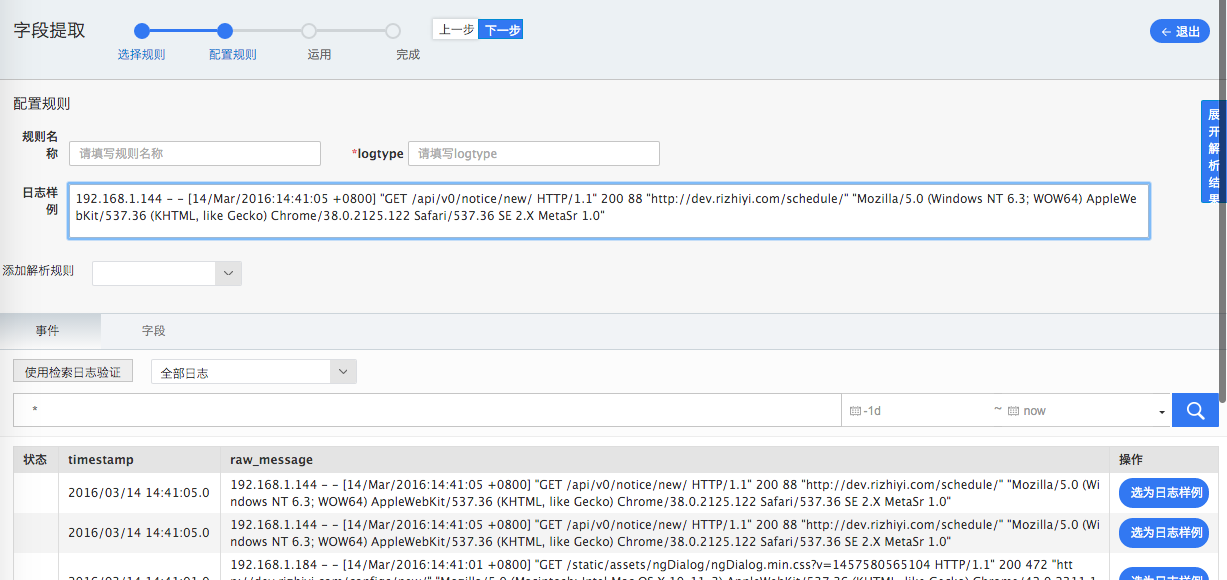
页面上“规则名称”和“logtype”必须填写。一般情况下,建议分别作为本次新建字段提取规则的中英文命名。logtype会作为后续解析字段的上层对象名存在。例如logtype:apache解析出来的clientip结果,字段名为apache.clientip。
添加配置规则
日志的格式是多样化的,为了解析这些多样的日志,通常需要多种方法来处理。日志易提供自定义日志格式配置功能,用户每次配置一项功能后,先解析,解析成功即可点击“继续”,再配置下一项功能。
配置规则
1. 正则解析
2. KeyValue分解
3. KeyValue正则匹配
4. 数值型字段转换
5. url解码
6. User Agent解析
7. 时间戳识别
8. geo解析
9. JSON解析
10. 字段值拆分
11. xml解析
12. syslog_pri解析
13. 自定义字典
14. 格式转换
15. 内容替换
1.正则解析
简介
正则是处理文本解析的有力工具。需要您了解一些基本的正则表达式知识:
\, ?, +, *, [], (?:) (?<key>value)
请参考正则语法
例如有这样一条日志:
2014-05-14 23:24:47 15752 [Note] InnoDB: 128 rollback segment(s) are active
我们希望提取出以下字段:timestamp,pid,loglevel和message,可以配置如下的表达式:
(?<timestamp>\S+ \S+) (?<pid>\S+) \[(?<loglevel>\S+\] (?<message>.*)
其中
\S表示匹配非空格字符,\S+表示匹配连续的非空格字符,(?<key>value) 表示提取名字为key的字段,其值为value,会解析出如下字段:
1 timestamp:2014-05-14 23:24:47
2 pid:15752
3 loglevel:Note
4 message:InnoDB: 128 rollback segment(s) are active
除了正常的正则表达式,我们还提供了一些常用的正则表达式,可以通过%{XXX}的方式来引用。比如可以使用%{NOTSPACE}来代替\S+,这样的正则表达式为:
(?<timestamp>%{NOTSPACE} %{NOTSPACE}) %{NOTSPACE:pid} \[%{NOTSPACE:loglevel}\] %{GREEDYDATA:message}
默认的字段值是string类型的,如果您想将其转换为number类型,可以在引用中加入type类型,目前仅支持int和float类型,例如:
%{XXX:int} 或者 %{XXX:float}
常用的正则表达式
1 基本:
%{NUMBER} (?:%{BASE10NUM})
%{POSINT} \b(?:[1-9][0-9]*)\b
%{NONNEGINT} \b(?:[0-9]+)\b
%{WORD} \b\w+\b
%{NOTSPACE} \S+
%{SPACE} \s*
%{MORESPACE} \s+
%{DATA} .*?
%{GREEDYDATA} .*
%{IP} 略
%{PORT} 略
2 Apache/Nginx:
%{ApcClientIP}
%{ApcIdent}
%{ApcUser}
%{ApcTimestamp}
%{ApcStatus}
%{ApcRespLen}
%{ApcReferer}
%{ApcUa}
%{ApcXForward}
%{ApcRequest}
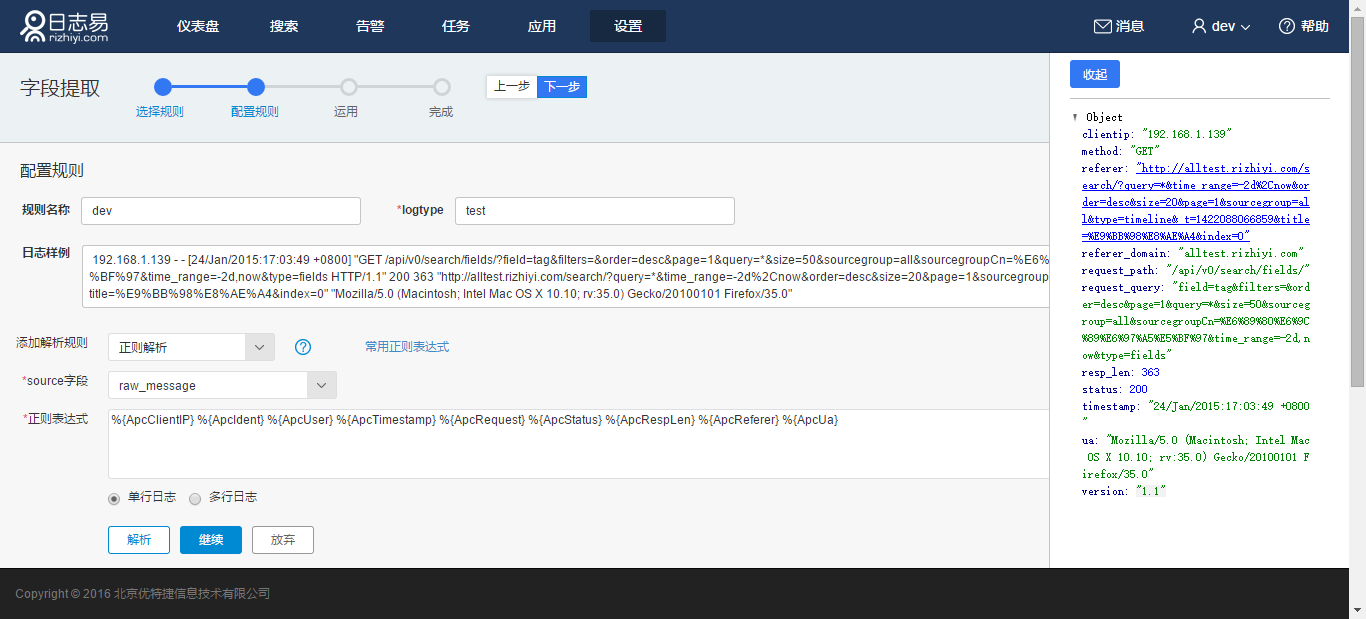
例如原始日志:
192.168.1.139 - - [24/Jan/2015:17:03:49 +0800] "GET /api/v0/search/fields/?field=tag&filters=&order=desc&page=1&query=*&size=50&sourcegroup=all&sourcegroupCn=%E6%89%80%E6%9C%89%E6%97%A5%E5%BF%97&time_range=-2d,now&type=fields HTTP/1.1" 200 363 "http://alltest.rizhiyi.com/search/?query=*&time_range=-2d%2Cnow&order=desc&size=20&page=1&sourcegroup=all&type=timeline&_t=1422088066859&title=%E9%BB%98%E8%AE%A4&index=0" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:35.0) Gecko/20100101 Firefox/35.0"
可以采用如下配置:
%{ApcClientIP} %{ApcIdent} %{ApcUser} %{ApcTimestamp} %{ApcRequest} %{ApcStatus} %{ApcRespLen} %{ApcReferer} %{ApcUa}
抽取出如下字段:
注意事项
正则库使用的是完全匹配模式,即正则表达式需要消耗掉整条日志才可以匹配:
%{IP:ip}:%{PORT:port} 不会匹配2014-10-20 192.168.1.1:8080和 192.168.1.1:8080 2014-10-20,只会匹配192.168.1.1:8080
一个正则表达式中字段分组命名的字段不能重复,如果命名的字段有. @或空格,它们都会被替换成下划线_,因此不要使用这些符号。
以下解析规则需要配置source(哪个字段),指定这个配置对哪个字段有效,也可以选择raw_message。
2.KeyValue分解
KV主要用来解析明显的KV字符串,例如上面的例子中正则表达式解析后,request_query字段为:
field=tag&filters=&order=desc&page=1&query=*&size=50&sourcegroup=all&sourcegroupCn=%E6%89%80%E6%9C%89%E6%97%A5%E5%BF%97&time_range=-2d,now&type=fields
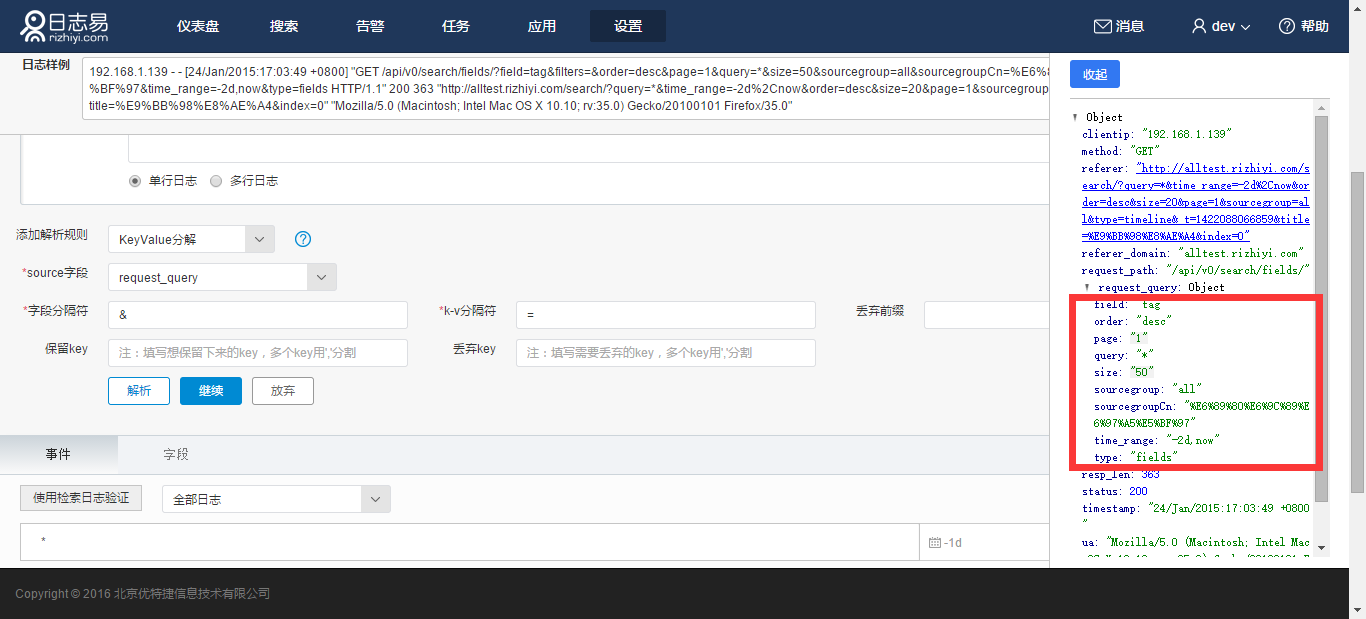
这是一个按照”&”和”=”来分割的KV字段。添加解析规则:KeyValue分解,source字段选择request_query,定义字段间分隔符为&,定义k-v分隔符为=,点击解析,如图可看到解析结果:
如果多个key,您可以通过填写key名称做保留或者取舍,也可以填写丢弃前缀名简化日志内容。
3.KeyValue正则匹配
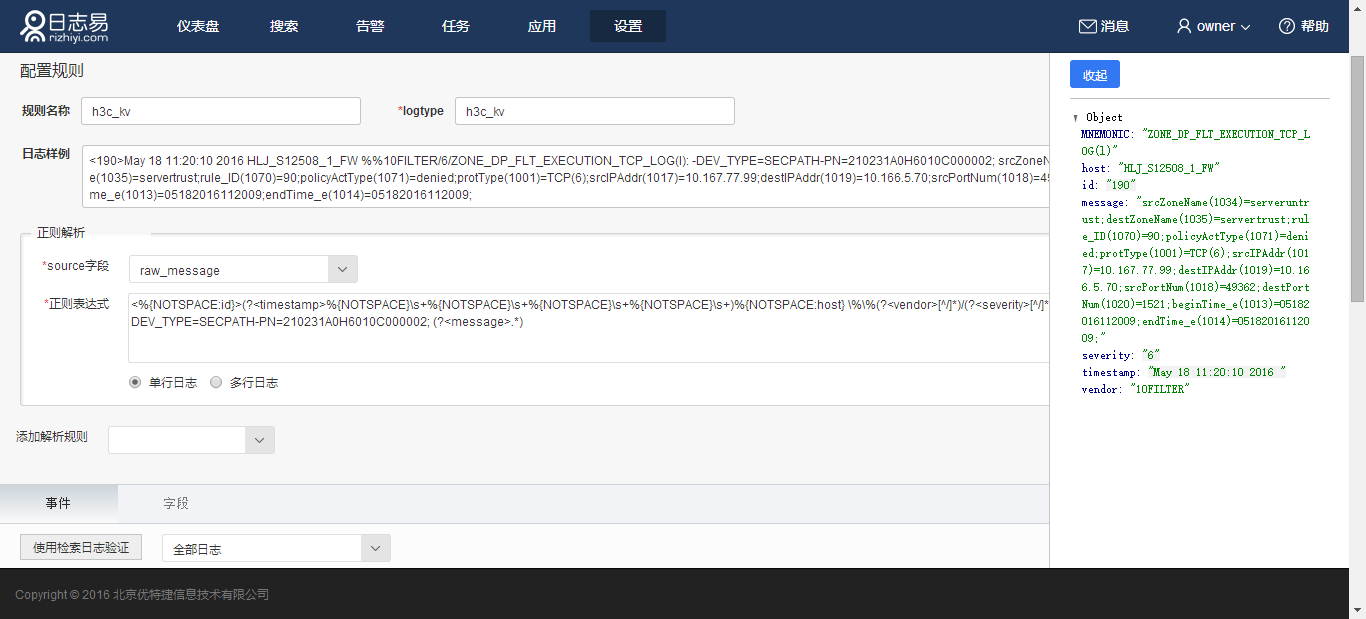
某些日志中KV字段可能比较复杂,用户往往希望查看解析后简单明了的字段格式,并丢弃某些无关紧要的字段,您可以使用KeyValue正则匹配的方式提取字段,例如一条日志为
<190>May 18 11:20:10 2016 HLJ_S12508_1_FW %%10FILTER/6/ZONE_DP_FLT_EXECUTION_TCP_LOG(l): -DEV_TYPE=SECPATH-PN=210231A0H6010C000002; srcZoneName(1034)=serveruntrust;destZoneName(1035)=servertrust;rule_ID(1070)=90;policyActType(1071)=denied;protType(1001)=TCP(6);srcIPAddr(1017)=10.167.77.99;destIPAddr(1019)=10.166.5.70;srcPortNum(1018)=49362;destPortNum(1020)=1521;beginTime_e(1013)=05182016112009;endTime_e(1014)=05182016112009;
先对日志正则匹配
<%{NOTSPACE:id}>(?<timestamp>%{NOTSPACE}\s+%{NOTSPACE}\s+%{NOTSPACE}\s+%{NOTSPACE}\s+)%{NOTSPACE:host} \%\%(?<vendor>[^/]*)/(?<severity>[^/]*)/(?<MNEMONIC>[^:]*): -DEV_TYPE=SECPATH-PN=210231A0H6010C000002; (?<message>.*)
然后针对“message”字段,进行KeyValue正则匹配的解析配置:

点击解析,可以看到解析结果
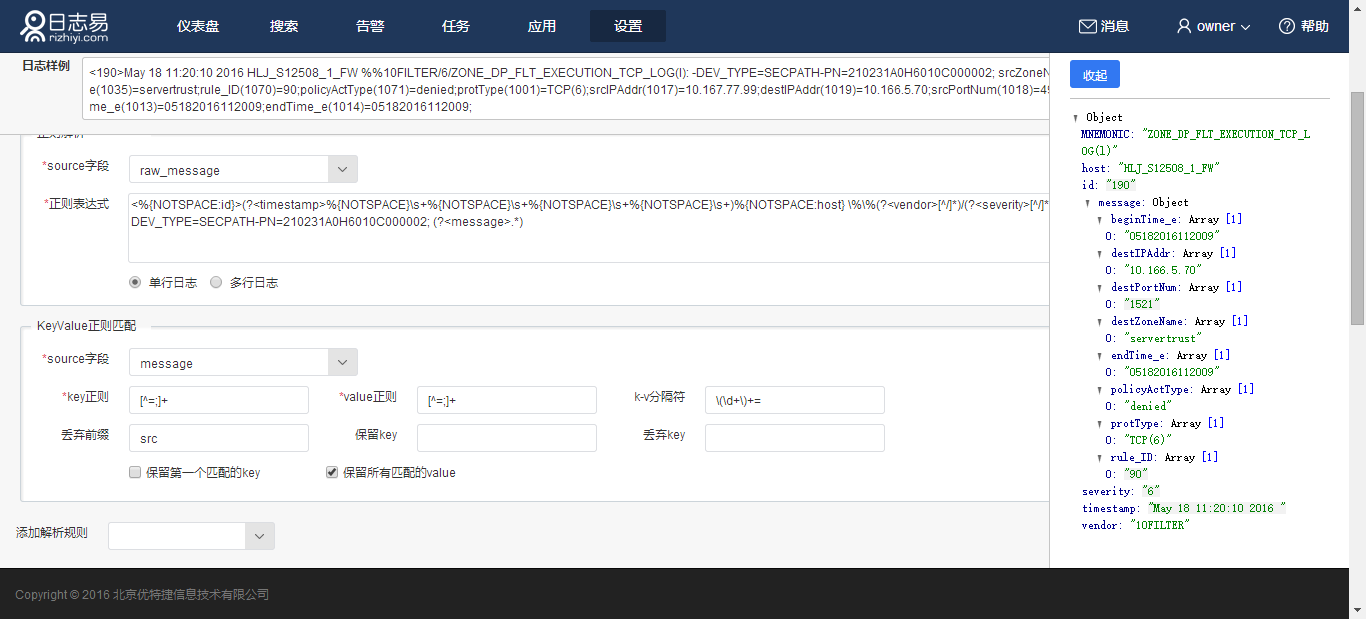
所有以src开头的字段都被丢弃,字段名被提取
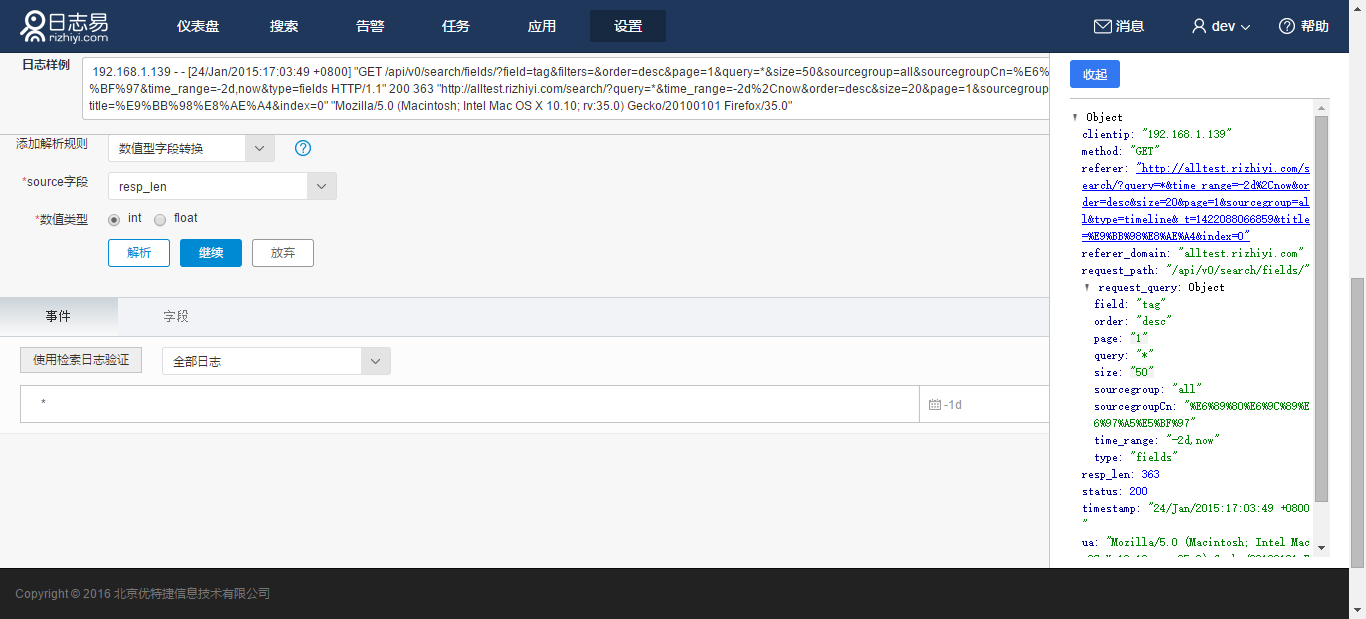
4.数值型字段转换
默认提取出来的字段都是字符串类型的。如果您希望将这个值转换成数值类型,以方便再后面做统计,则需要通过这个功能来做转换。转换时需要您配置数值的类型:int/float
例如: 您的日志经过解析得出如下字段:
k1: "123",
k2: "123.0"
经过转换可以转变为:
k1: 123,
k2: 123.0
如针对正则表达式的解析结果,选择resp_len字段,点选“int”,点击解析:
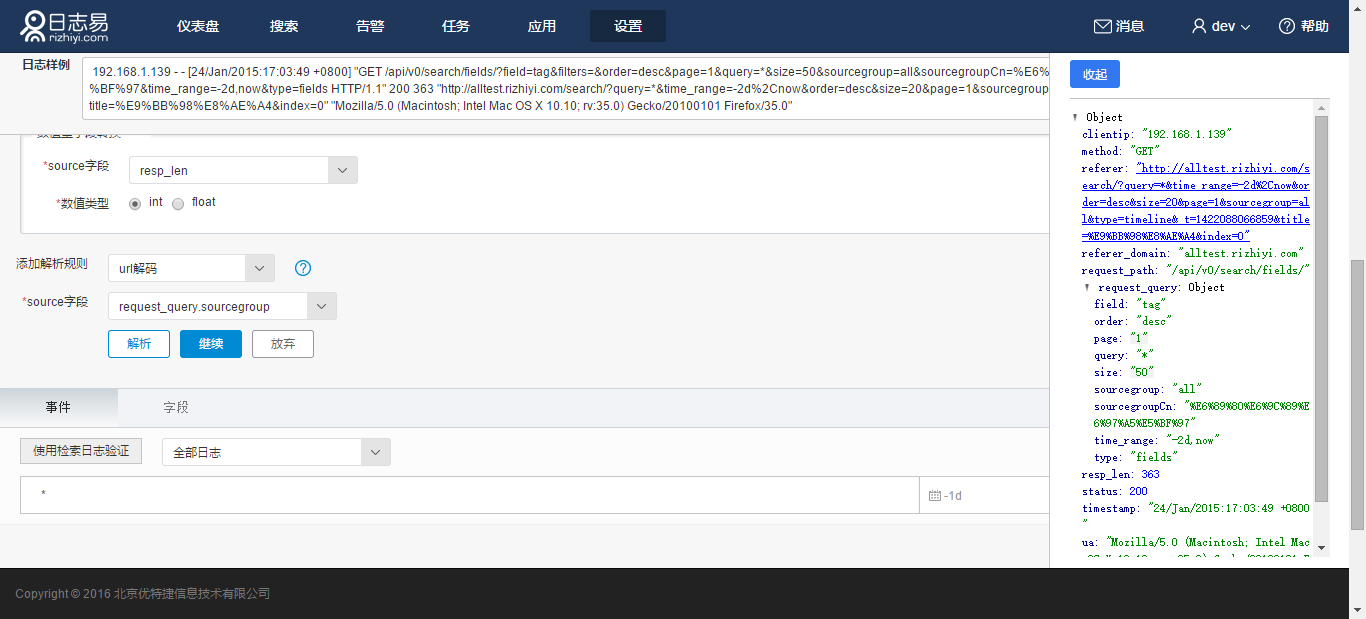
5.url解码
将编码过的url进行解码,这个操作只能针对已经解析出来的字段。 如针对正则表达式的解析结果,选择字段request_query.sourcegroup,点击解析:
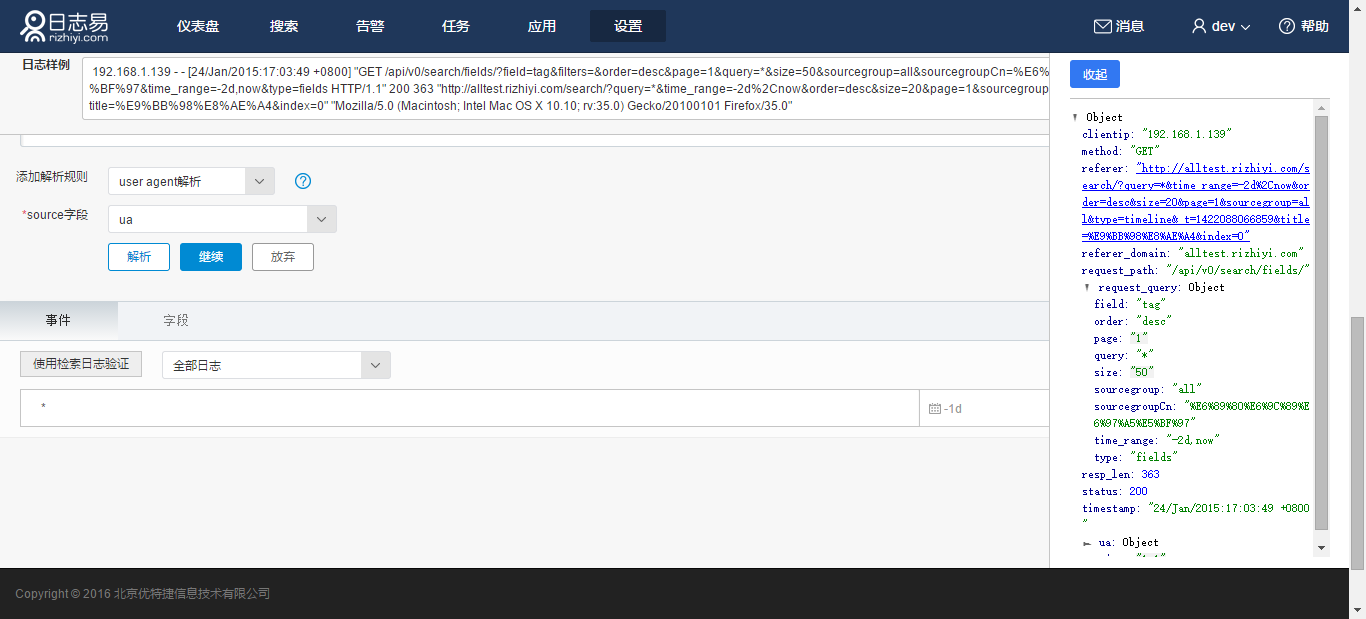
6.User Agent解析
分析HTTP日志中User Agent的用户操作系统和浏览器信息。如针对正则表达式解析后的结果,选择ua字段,点击解析:
7.时间戳识别
使用者通常关心日志发生的时间,比如检索最近几天的日志,需要转换日志中的timestamp字段的内容,日志易系统就可以识别这条日志的时间戳。这就需要您在之前抽取字段时就提取出timestamp字段。例如:
timestamp: "150120 16:00:30"
需要配置解析类型为:
yyMMdd HH:mm:ss
具体的配置格式参考:
| 符号 | 含义 | 格式 | 举例 |
| e | 星期 | 数字 | 星期二: e:2 ee:02 |
| E | 星期 | 文本 | 星期二: E:Tue EEEE:Tuesday |
| M | 月份 | 月 | 七月: M:7 MM:07 MMM:Jul MMMM:July |
| d | 一月的第几天 | 数字 | 第9天 d:9 dd:09 |
| H | 0-23小时 | 数字 | 8点 H:8 HH: 08 |
| m | 0-59分钟 | 数字 | 8分 m:8 mm:08 |
| s | 0-59毫秒 | 数字 | 8秒 s:8 ss:08 |
| S | 0-999毫秒 | 数字 | 888毫秒 SSS:888 |
| z | 时区 | 文本 | zzz:PST zzzz:Pacific Standard Time; |
| Z | 时区 | 时区 | Z: +0800; ZZ: +08:00; ZZZZ: America/Los_Angeles |
如果符合ISO8601标准可以直接配置成”ISO8601”,例如:Fri Jul 05 21:28:24 2013 ISO8601,
如果是UNIX格式可以直接配置成”UNIX”,例如:1412899200.000,
如果解析失败或者没有配置,默认使用进入系统的时间作为这条日志发生的时间。
对上面例子中的日志时间戳进行配置,source字段选择timestamp,填入“dd/MMM/yyyy:HH:mm:ss Z”,选择时区和时间戳语言,点击解析,弹出配置成功窗口如下图:
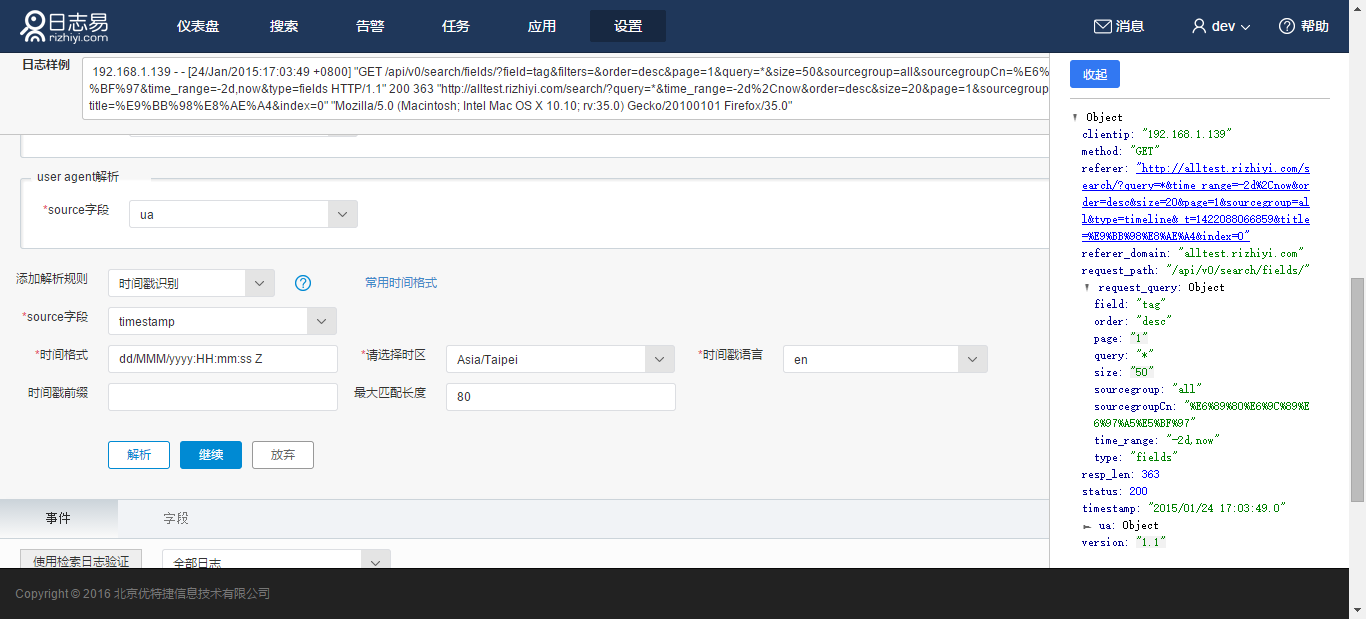
针对特殊格式的时间戳格式,您可以选择设定时间戳前缀和最大匹配长度,更好的解析日志。
8.geo解析
解析出日志中ip地址的地理位置,例如针对上面日志,添加“geo解析”解析规则,选择“clientip”字段:
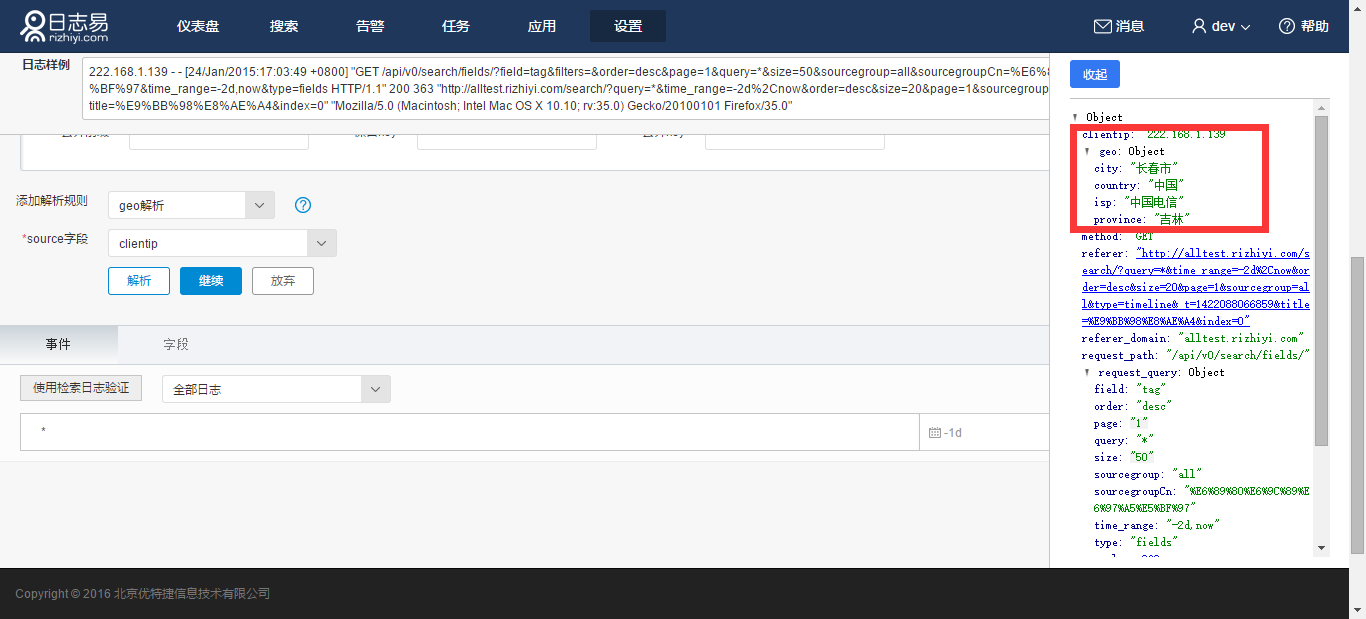
可以看到clientip地址被解析出国家与城市等信息。
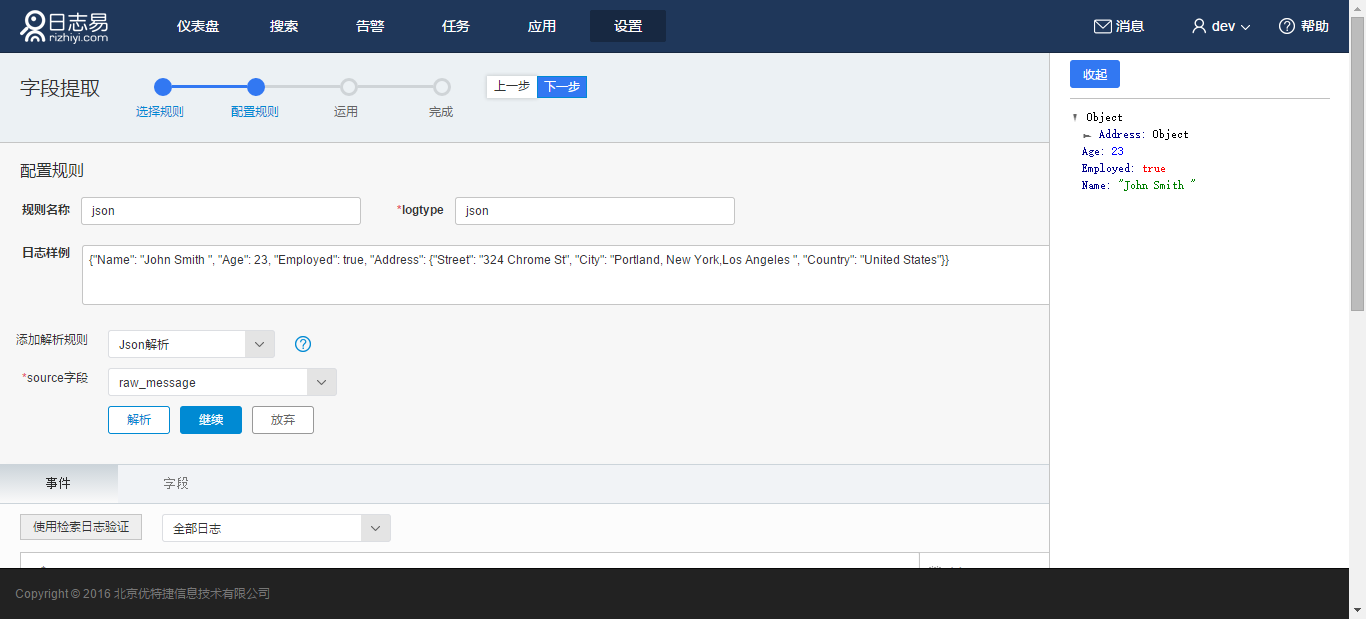
9.JSON解析
JSON解析用来解析JSON格式的日志, 例如原始日志为:
{"Name": "John Smith ", "Age": 23, "Employed": true, "Address": {"Street": "324 Chrome St", "City": "Portland, New York,Los Angeles ", "Country": "United States"}}
JSON解析后如下图所示:
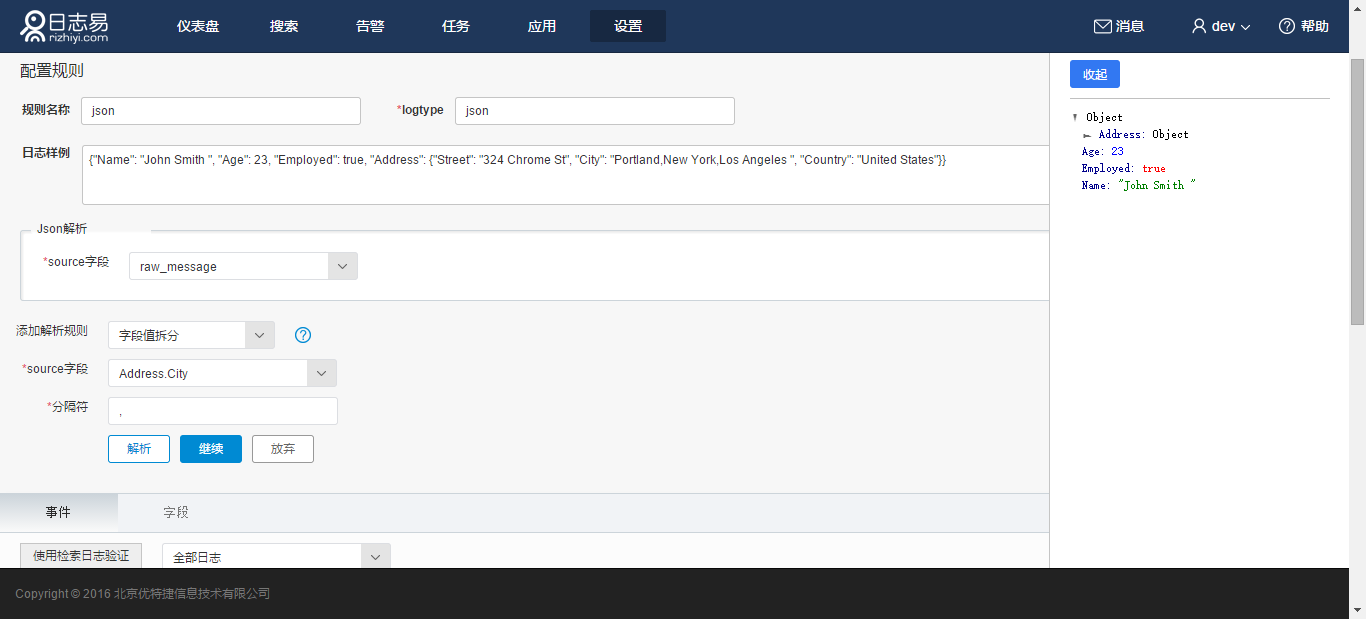
10.字段值拆分
将字符串切分,例如:
key:"1.2.3.4, 2.4.5.6"
可以根据“,”来对其进行切分成两个value:
key:["1.2.3.4", "2.4.5.6"]
在上面的JSON解析结果中,Address.City字段内容为 “Portland,New York,Los Angeles “,将其作为source字段,将分隔符设定为“,”,点击解析,即得到解析结果如图所示:
11.xml解析
针对xml格式的日志解析
12.syslog_pri解析
针对syslog_pri日志格式的解析
13.自定义字典
关于自定义字典部分,请参考字典管理部分
14.格式转换
针对IP地址的转换,用于将一个长整数地址转换成一个字符串(IPv4)网络标准点格式地址,例如3651919938 使用格式转换即会转变成 217.171.224.66
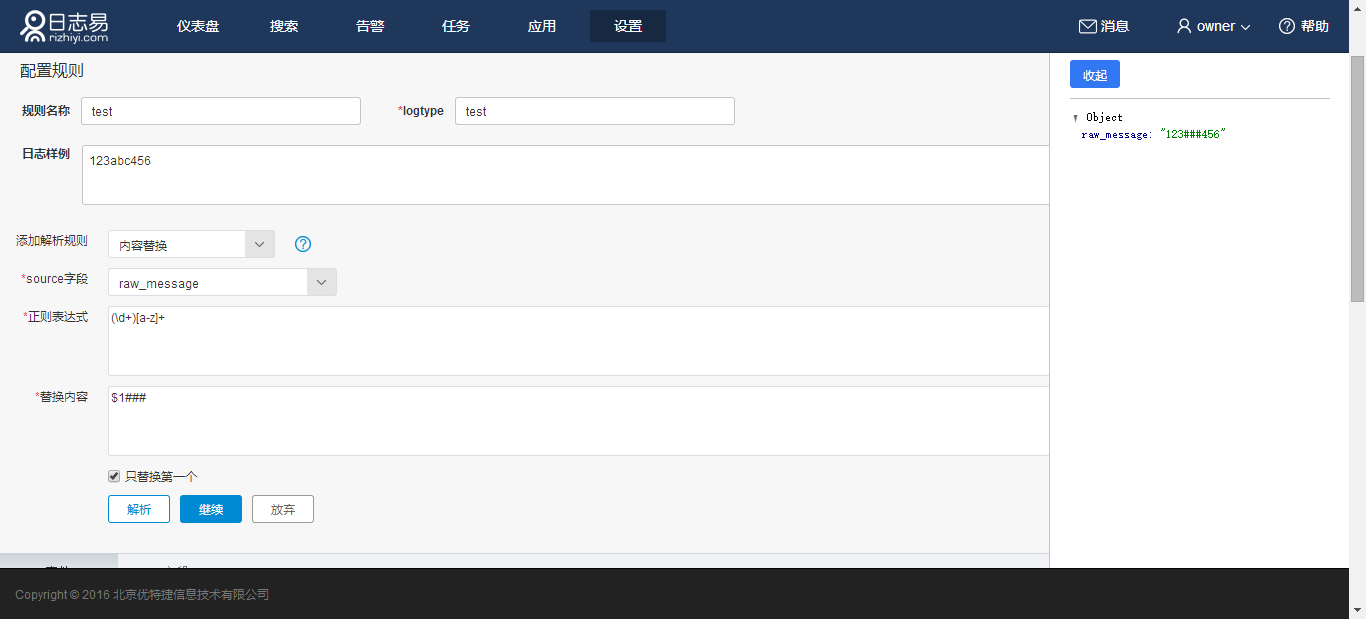
15.内容替换
用于对敏感信息的替换,例如日志原文为
123abc456
正则表达式为(\d+)[a-z]+,替换内容为$1###。 则日志原文变成
123###456
完成所有解析规则配置后。点击“使用检索日志验证”,事件表格左侧出现对错图标,每行日志可以单独展开自己的解析结果;

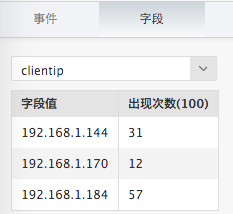
点击“字段”标签,下拉框选择字段名,可以查看在最近100条日志中,该解析规则提取出来的字段效果统计排行。
可以通过“全部日志,解析成功,解析失败”下拉框过滤被验证的事件;
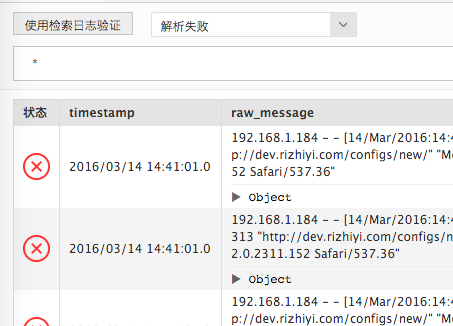
在解析失败的事件集上重新点击“选为日志样例”,替换之前的“日志样例”文本框;
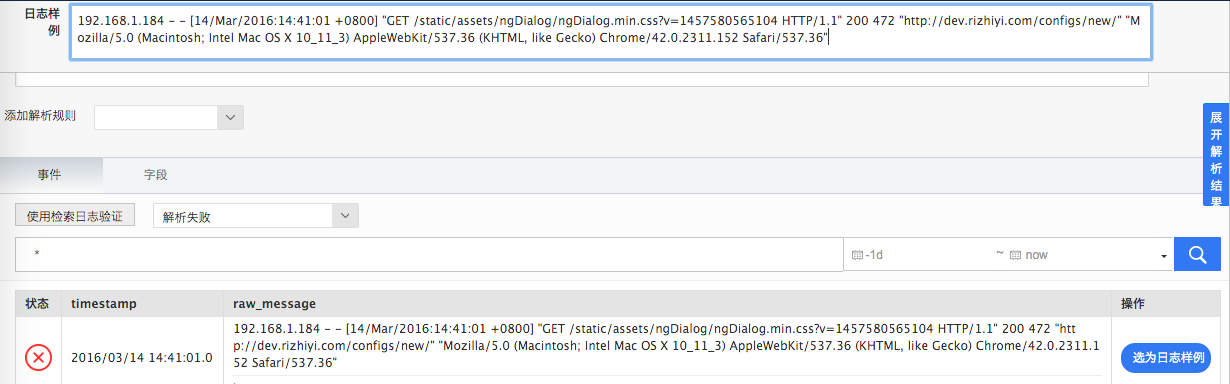
完成规则配置,点击“下一步”,进入规则运用界面。在这里填写“appname”和“tag”,tag内容可选择填写,表示该appname里,带有这个tag的日志,在进入日志易系统时,会运用该解析规则进行日志解析:
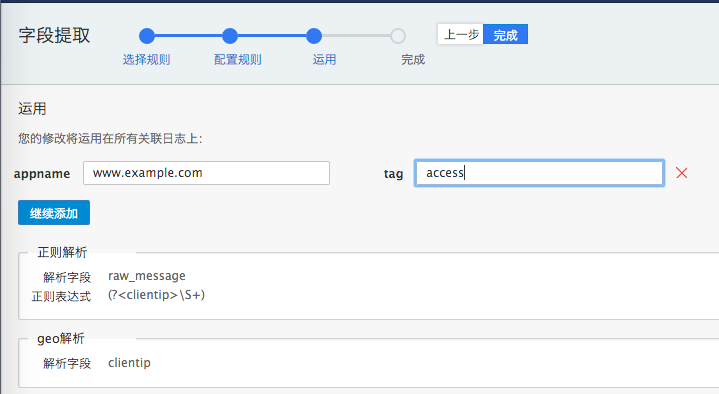
可以添加多个appname。表示多个appname都使用这个解析规则。
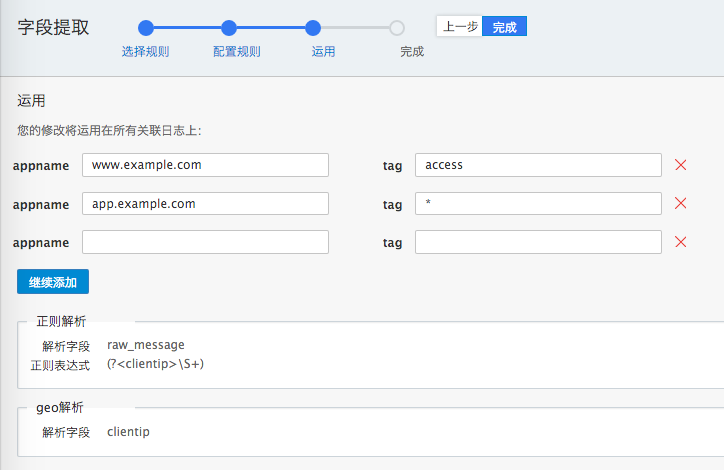
页面下方显示该规则的概要。 点击“完成”。返回查看”字段提取”列表,出现新规则和对应的 appname/tag。
从已有规则快速新建
点击“新建”,选择“已有规则”,比如 apache,点击“下一步”:
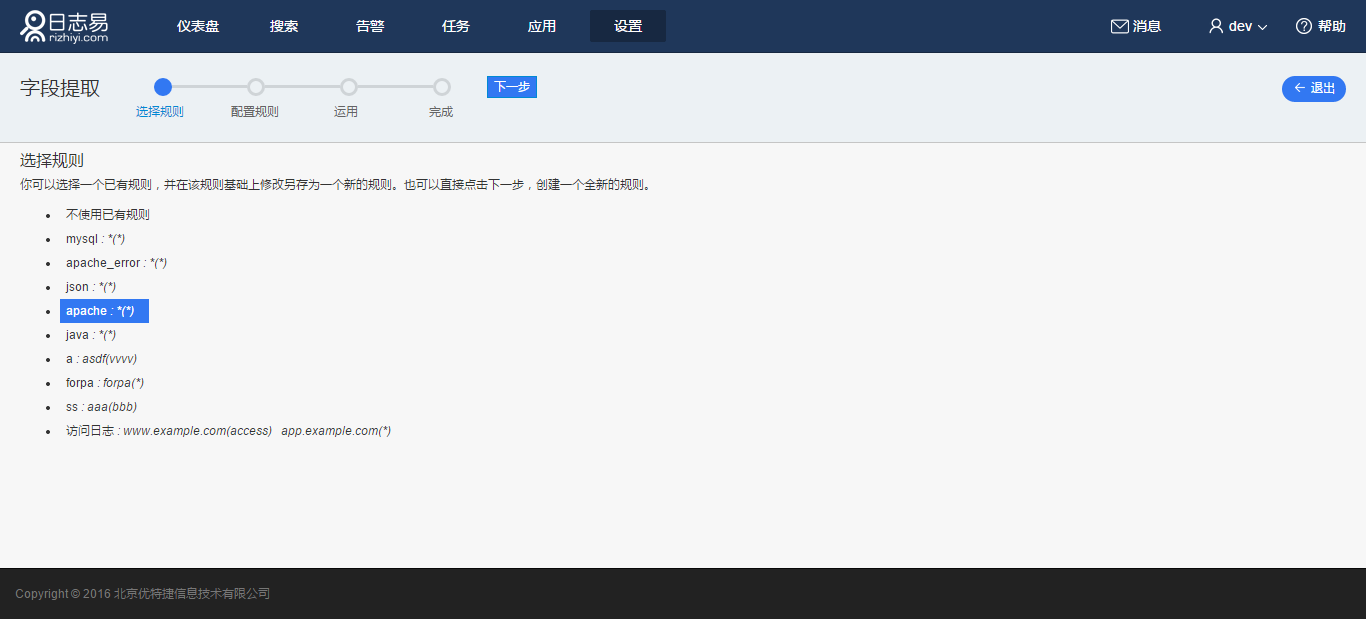
进入“配置规则”页,页面展示 apache 解析规则,但是“规则名称”留空,必须自定义新的规则名称。logtype 则按需填写,可重复。
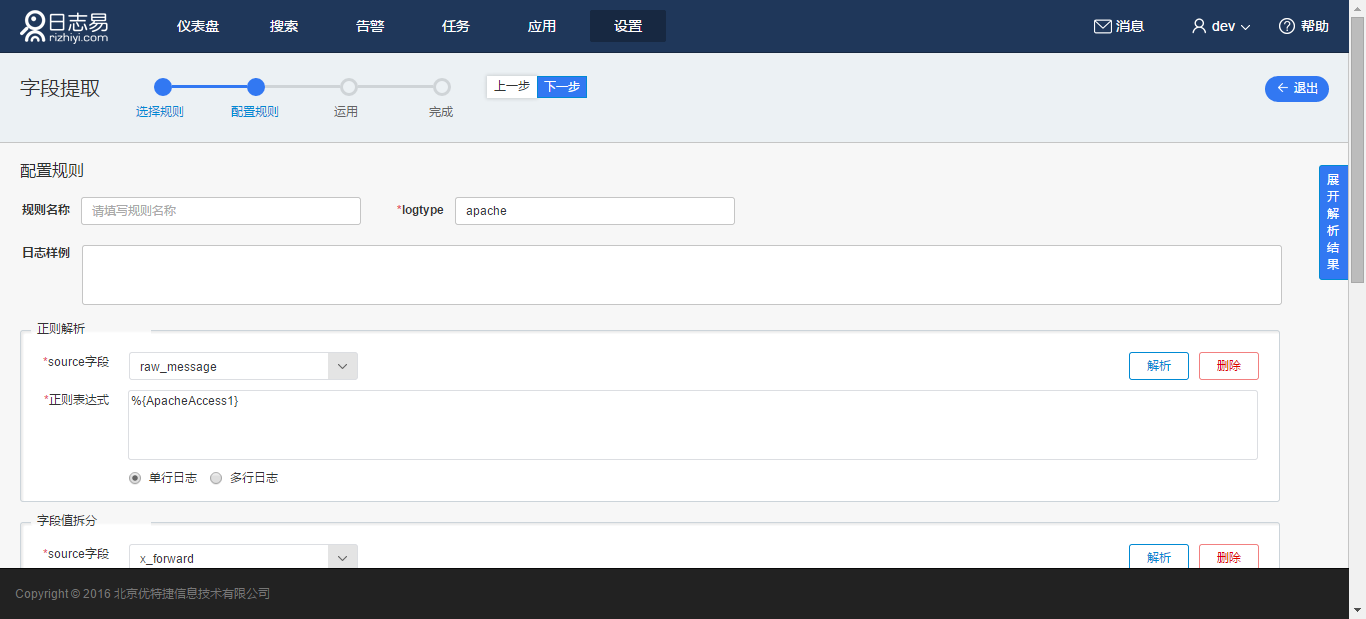
其余流程同上。
编辑已有规则
点击已有规则的“编辑”按钮,进入“配置规则”页。 修改“解析规则”,点击“下一步”,进入“运用”页。点击“完成”。
将已有规则运用到其他 appname/tag 上
点击已有规则的“编辑”按钮,进入“配置规则”页。 点击“下一步”,进入“运用”页。修改运用的 appname/tag。点击“完成”。